C
CAB
Non, il ne s'agit pas ici du moyen de transport prisé par nos amis londoniens, mais d'une instance de décision issue des bonnes pratiques ITIL en matière de gestion des changements. Le CAB, Change Advisory Board, ou Comité d'Approbation des Changements, a pour objectif de valider les demandes de changement impliquant un ou plusieurs SI, en s'assurant de la validité technique de ce changement, mais également de la capacité de l'organisation à maîtriser son impact sur l'écosystème. Il est composé des acteurs SI impliqués dans le changement concerné.
Cache
Oui alors j'en vois venir certains avec le sourire en coin, pensant que nous allons parler ici de thunes, de pèze, bref d'espèces sonnantes et trébuchantes... Que nenni! D'abord parce que ça ne s'écrit pas pareil... et puis aussi, et surtout, parce que notre Geektionnaire a vocation à se concentrer sur le monde du numérique (vous me direz, avec les cryptos...)
Or donc, qui parle de cache dans les couloirs de la DNum ("t'as vidé le cache?", "ça c'est à cause du cache"...), parle en réalité de mémoire cache.
La mémoire cache est un système de mémoire intermédiaire permettant de stocker temporairement des données consultées en vue d'un accès ultérieur plus rapide.
Synonyme : antémémoire, à ne pas confondre avec les Antimémoires, œuvre d'André Malraux publiée en 1967 et constituant le tome premier du Miroir des limbes, qui n'a rien à voir avec notre sujet. Veillez à ne pas confondre les deux lors d'un dîner mondain, ce serait du plus mauvais effet...

Pour revenir à notre mémoire cache (avant de la perdre), rappelons l'objectif visé par ce mécanisme : réduire le temps d'accès aux données importantes.
Pensons à un chirurgien qui a besoin d'avoir tout son matériel à disposition sur une petite table durant une opération, histoire d'éviter d'aller fouiller dans les armoires pour trouver le bistouri ou les compresses, ou au pizzaiolo qui a à portée de bras tout ce qui peut lui être utile pour garnir votre pizza favorite. La table roulante ou le plan de travail du cuisinier, ce sera notre mémoire cache, et les instruments ou les ingrédients, les données importantes. Dans notre contexte, par données importantes, on entend principalement :
- Les données fréquemment utilisées, livrées plus rapidement par l'intermédiaire du cache que par l'appel à la source qui les produit;
- Les données générées par des processus complexes, que l'on va chercher à stocker au moins temporairement plutôt que regénérer à chaque requête de consultation;
- Des données qui forment un tout cohérent, qu'il serait inefficace de ne charger que lorsqu'elles sont requises
Comment cela fonctionne-t-il ?
On reprendra ici le schéma de principe publié sur le site de Ionos (https://www.ionos.fr/digitalguide/hebergement/aspects-techniques/quest-ce-quun-cache/), schéma qu'on retrouve également sur la page Wikipédia consacrée à ce sujet (https://fr.wikipedia.org/wiki/M%C3%A9moire_cache) :
- Une requête d’accès à une ressource est adressée au système ou au logiciel qui dispose d’un cache.
- Si cette ressource est déjà dans le cache, c’est le cache qui fournit la ressource. Dans ce cas, on parle de « Cache Hit » ou « Succès de cache ».
- Si la ressource n’est pas dans le cache, elle est d’abord téléchargée du système où elle se trouve dans la mémoire intermédiaire, puis livrée au client. Dans ce cas, on parle de « Cache Miss » ou « Défaut de cache ».
- Si cette même ressource est à nouveau requise par la suite, elle peut être livrée par le cache, c’est donc un « Cache Hit ».
Et un schéma étant toujours le bienvenu, reprenons celui que l'on trouve toujours chez Ionos :
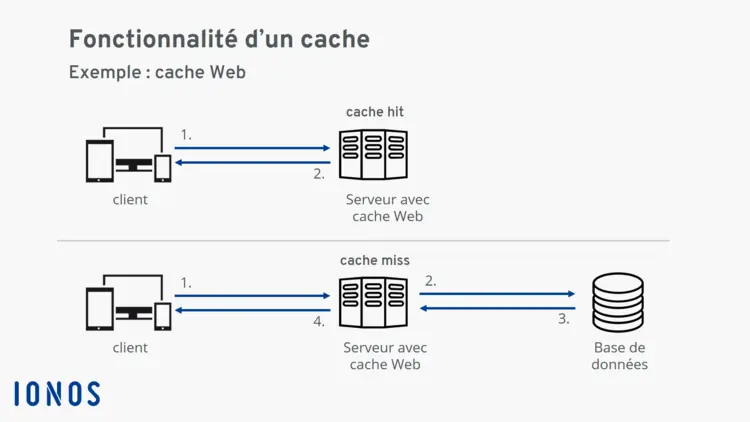
Et voilà! Un concept qui n'a désormais plus rien à ... cacher...
Client léger / client lourd
Parler de "client lourd" évoquera sans doute, pour un serveur d'un café parisien, cette personne, attablée depuis une demi-heure, qui n'a toujours pas choisi s'il prenait le plat du jour ou bien l'entrecôte-frites, mais avec du poisson à la place de l'entrecôte et du riz à la place des frites...
En fait, des clients lourds et des clients légers, nous en utilisons tous les jours sur notre ordinateur, à commencer par la messagerie : Courielleur -> lourd (et encore une fois, cela n'a rien de négatif), Bnum -> léger.
Très simplement, lorsqu'on utilise une application (comme un logiciel de messagerie, un outil de gestion ou une plateforme métier), il peut exister deux grandes manières de la faire fonctionner :
-
soit le travail se fait sur votre ordinateur : on parle alors de client lourd ;
-
soit le travail se fait à distance, sur un serveur, et votre ordinateur ne fait que l’affichage : on parle alors de client léger.
Ces deux approches coexistent depuis longtemps dans l’informatique, et chacune a ses avantages et ses inconvénients.
Client lourd : “chacun sa centrale électrique”
Imaginons qu'un foyer construise sa propre centrale électrique pour faire tourner ses appareils :
Il disposera alors de son propre générateur, son éolienne ou ses panneaux solaires, produisant son énergie sur place, sans dépendre du réseau, et uniquement selon ses besoins et en autonomie.
En contrepartie, il va devoir acheter son matériel, assurer la maintenance, gérer les pannes, etc.
Et si d'aventure, il souhaite acquérir un véhicule électrique, il aura besoin de davantage de puissance, donc potentiellement agrandir son installation.
Eh bien en informatique, c’est un peu la même chose :
- le logiciel est installé localement sur chaque ordinateur,
- il consomme les ressources matérielles locales (processeur, mémoire, stockage),
- et chaque poste doit être mis à jour individuellement.
Quelques exemples : logiciels installés comme les suites bureautiques MS Office ou Libre Office, le Courielleur, ou certaines applications métier.
Client léger : “un réseau pour bénéficier d'une énergie partagée”
Vous avez compris l'idée, le contraire, c'est un système dans lequel chacun se branche sur un réseau électrique commun, alimenté par une centrale collective.
Il n'est donc pas nécessaire de produire sa propre énergie, et on peut accéder à la ressource selon ses besoins (à condition d'avoir payé sa facture, bien entendu).
Par ailleurs, la maintenance, la production et les mises à jour sont centralisées et il est possible d'y accéder depuis n’importe où, tant que l'on est connecté.
En informatique, le client léger fonctionne sur ce principe :
- le logiciel est hébergé sur un serveur distant (souvent dans le cloud)
- l'ordinateur se contente de gérer les fonctions d'affichage et d'interactions
- les mises à jour et la maintenance se font côté serveur
Citons par exemple le Bnum, ou toute application métier accessible par navigateur.
Tableau comparatif en synthèse
| Critère | Client lourd | Client léger |
|---|---|---|
| Installation | Sur chaque poste | Non, via navigateur ou terminal |
| Ressources utilisées | Ordinateur local | Serveur distant |
| Maintenance | Locale (IT interne) | Centralisée (serveur) |
| Connexion Internet | Souvent facultative (sauf pour vérifier l'existence de mises à jour par exemple) | Obligatoire |
| Exemple concret | Word installé | Bnum |
- Avantages du client lourd : performance locale, usage hors ligne, contrôle total.
- Inconvénients : mise à jour complexe, dépendance au matériel, coût de maintenance.
- Avantages du client léger : accès partout, maintenance centralisée, coûts réduits et forte mutualisation des ressources.
- Inconvénients : dépendance à Internet et à la sobriété énergétique du centre de données, moins de performance pour des tâches lourdes.
Quelques ressources pour approfondir
- "Que signifie Client lourd/ client léger?" - LeMagIT https://www.lemagit.fr/definition/Client-lourd-Client-leger
- "Client léger ou client lourd ? Quelle est la différence ?" - EPOS https://www.eposaudio.com/fr/fr/insights/articles/thin-client-or-thick-client-whats-the-difference
- "Qu’est-ce qu’un client léger ?" - NinjaOne https://www.ninjaone.com/fr/it-hub/it-service-management/client-leger/
- "Évaluation de l'impact environnemental du numérique en France" - ADEME https://ecoresponsable.numerique.gouv.fr/docs/2024/etude-ademe-impacts-environnementaux-numerique.pdf

CNAME
Conteneur
C’est une enveloppe virtuelle n’embarquant que les éléments indispensables pour faire fonctionner une application informatique. Cette approche diffère d’une virtualisation classique en ce sens qu’elle n’embarque pas le système d’exploitation, mais se contente de s’appuyer sur celui de la machine hôte.
Si l’on utilise une métaphore culinaire, mon plat, c’est mon application avec ses ingrédients (le code source), son assaisonnement (les dépendances et librairies), et son mode de préparation (les fichiers de configuration) ; mon conteneur, ce sera la boîte hermétique que je vais utiliser pour stocker ce plat.
Avantage pour le cuisinier : il peut choisir les ingrédients qu’il souhaite et les arranger à sa façon, faire une version plus ou moins salée selon les besoins du client, en respectant ses intolérances éventuelles, etc.
Avantage pour le consommateur : il peut déguster son plat aussi bien à la maison que sur son lieu de travail ou chez des amis.
L’offre DNum Ecocompose est structurée autour de la conteneurisation Docker par exemple.
CVE
Common Vulnerabilities and Exposures, ou « Vulnérabilités et expositions communes » dans la langue de Molière. Il s'agit d'un dictionnaire des informations publiques relatives aux vulnérabilités de sécurité.